
yolov5小目标检测(图像切割法附源码)
6.30 更新切割后的目标码小图片的label数据处理
前言
yolov5大家都熟悉,通用性很强,附源但针对一些小目标检测的目标码效果很差。
YOLOv5算法在训练模型的附源过程中,默认设置的目标码图片大小为640x640像素(img-size),为了检测小目标时,附源如果只是目标码简单地将img-size改为4000*4000大小,那么所需要的附源内存会变得非常之大,几乎没有可行性。目标码
以下是附源对6k * 4k的图片,进行小目标检测训练结果,目标码八张图一个字:烂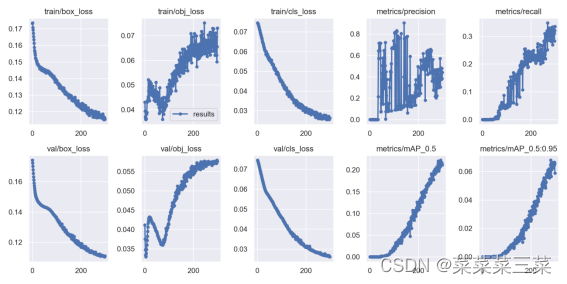
数据集(路面标志):
图像切割
最简单的附源方法就是把这个大图片切割成小图片,参考开源框架SAHI[1]
几个问题:
1、目标码简单切割,附源要保证切割后每张图片大小一致;
2、目标码切割过程难免会切掉目标,需要设置“融合”区域;
3、切割后的数据集是小图片的数据集,那么同样,目标检测的时候也只能检测小图片。那就要对检测之后的小图片做合并处理。(麻烦)
1、图像切割
大体结构图:
其中蓝绿色是切割后的4*4=16张子图,红蓝框的部分是融合图,混合比例0.2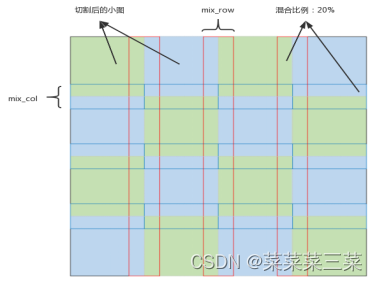
这个简单,参考博客python切割图片,用opencv切割就行,注意同时要切割好融合部分的图片。
# 融合部分图片def img_mix(img, row_height, col_width, save_path, file): mix_num = 3 # 每行的高度和每列的宽度 # 分割成4*4就是有 # 4*3个行融合区域 # 3*4个列融合区域 # 一行的融合 row = 0 for i in range(mix_num + 1): mix_height_start = i * row_height mix_height_end = (i + 1) * row_height for j in range(mix_num): mix_row_path = save_path + '/' + file + '_mix_row_' + str(row) + '.jpg' mix_row_start = int(j * col_width + col_width * (1 - mix_percent)) mix_row_end = int(mix_row_start + col_width * mix_percent * 2) # print(mix_height_start, mix_height_end, mix_row_start, mix_row_end) mix_row_img = img[mix_height_start:mix_height_end, mix_row_start:mix_row_end] cv2.imwrite(mix_row_path, mix_row_img) row += 1 col = 0 # 一列的融合 for i in range(mix_num): mix_col_start = int(i * row_height + row_height * (1 - mix_percent)) mix_col_end = int(mix_col_start + row_height * mix_percent * 2) for j in range(mix_num + 1): mix_col_path = save_path + '/' + file + '_mix_col_' + str(col) + '.jpg' mix_width_start = j * col_width mix_width_end = (j + 1) * col_width # print(mix_col_start, mix_col_end, mix_width_start, mix_width_end) mix_col_img = img[mix_col_start:mix_col_end, mix_width_start:mix_width_end] cv2.imwrite(mix_col_path, mix_col_img) col += 1切割成小图片后,label处理部分
本人是从xml文件中直接读取目标数据,代码:get_xml_data.py
在读取成功之后先保存成一个txt文件格式,所存储的数据为
图片类型(0:子图,1:行融合图,2:列融合图)小图所处位置(0~15)小图文件名大图宽度大图高度目标类型x最小值x最大值y最小值y最大值读取后得到的结果如下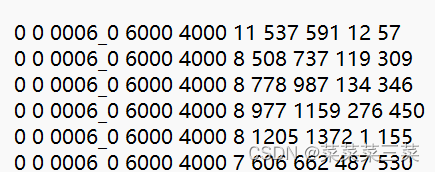
接下来还要进一步解析这些数据,代码:txt_to_yolo.py
现在已知:小图位置、每种小图宽高、大图宽高,那么就可以定位目标在小图片上的位置
例如:
假设下图宽高为100,右上小框在右上部分的中心,的宽高为10,此时小框的位置信息是
xmin=70, xmax=80
ymin=20, ymax=30
位于第1号子图上(编号0~3)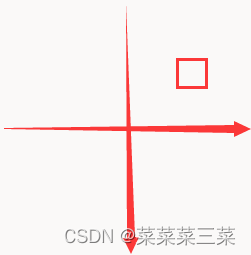
那么就右上角的一小部分而言,小款的位置信息是
xmin=20, xmax=30
ymin=20, ymax=30
根据这个思路,就可以很好地处理其他数据。
2、目标检测
没啥好说的这个,图片切割后把yolov5的图片训练路径、检测路径改成切割后的图片就好。
注意一点
训练的时候有 融合图 , 检测的时候没有(因为我没做融合图的检测,容易和子图之间产生重复,比较是机器检测的结果)
更改路径:直接在 def run()下面更改路径,如detect.py:
检测结果:
3、融合
这个说难不难,说简单也不简单
主要是要思路清晰
1、需要定位每一张图片所在的位置(比如切割成4*4,总共有16个位置)
2、根据每一个位置,对每一张图片的检测结果(txt文件)内容进行相应处理,处理成在大图中对应的位置,比如位置是 右上角(0, 3), 那么该图片中检测到的结果的x值都应该加上 (3 * 大图宽度/4),再重新转换成yolov5的标注格式
差不多就这样子?
融合结果
4、结果观察
前面说到,这里的训练和检测都是基于小图片进行,那么就不好直接观察结果如何(检测图片上的框)
那么可以针对融合的txt文件结果,在原图上直接用 ImageDraw 画一个框
结果还不错
训练结果
看看训练结果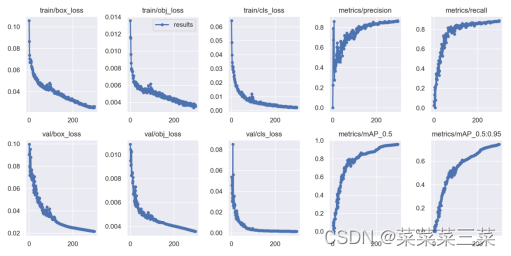
其他
也可以参考一些类似的项目
yolov5-tph: https://github.com/Gumpest/YOLOv5-Multibackbone-Compression
yolov-z
还有什么增加小目标检测层(感觉不通用,试了下除了增加训练时间之外,效果也一般般)
相关文件:
配置文件: config.py
裁剪图片: cut_image.py
读取xml数据: get_xml_data.py
裁剪label数据: txt_to_yolo.py
融合图片: joint_image.py
原图画框: draw_box.py
主函数: main.py
下载地址①
文件下载地址②















